Review
基于参数的评分函数。该函数将原始图像像素映射为分类评分值。
损失函数。该函数能够根据分类评分和训练集图像数据实际分类的一致性,衡量某个具体参数集的质量好坏。损失函数有多种版本和不同的实现方式(例如:Softmax或SVM)。 Softmax 和 SVM 不应该包括了score function 和 lost function
最优化Optimization。最优化是寻找能使得损失函数值最小化的参数W的过程。
损失函数可视化
在一维尺度上 $$L(W+aW_1)$$ x轴是a, y轴是loss function
在二维尺度上 $$L(W+aW_1+bW_2)$$, a,b 表达x轴, y轴, loss function 用颜色表示
单独的损失函数表示:
$$w_j$$ 如果对应分类正确即是负号,错误即是正号 $$L = \sumL/n$$
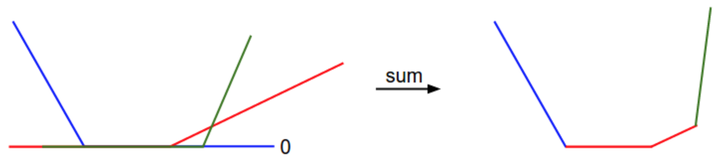
SVM的损失函数是一种凸函数,可以学习一下如何高效最小化凸函数,在这种损失函数会有一些不可导的点(kinks)
两个新概念:
- 梯度? 次梯度?未来学习点
最优化 Optimization
对于神经网络的最优化策略有:
策略#1:随即搜索 最差劲的搜索方案(base line)
# 假设X_train的每一列都是一个数据样本(比如3073 x 50000)
# 假设Y_train是数据样本的类别标签(比如一个长50000的一维数组)
# 假设函数L对损失函数进行评价
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)
感觉跟那个monkey sort 差不多 随机生成W weight。
# 假设X_test尺寸是[3073 x 10000], Y_test尺寸是[10000 x 1]
scores = Wbest.dot(Xte_cols) # 10 x 10000, the class scores for all test examples
# 找到在每列中评分值最大的索引(即预测的分类)
Yte_predict = np.argmax(scores, axis = 0)
# 以及计算准确率
np.mean(Yte_predict == Yte)
# 返回 0.1555
策略是:随机权重开始,然后迭代取优,从而获得更低的损失值。
策略#2:随机本地搜索
生成一个随机的扰动 $$ \delta W $$
$$ Wtry = W + \delta W $$
当 Wtry 的loss 变小的时候, 才决定移动
W = np.random.randn(10, 3073) * 0.001 # 生成随机初始W
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)
策略#3:跟随梯度
策略1 和 策略2 都是尝试好几个方向来找减少loss的方向,其实可以用梯度(gradient)来找到最陡峭的方向减少loss,
一维求导公式: d(fx)/dx
当函数有多个参数的时候,我们称导数为偏导数。而梯度就是在每个维度上偏导数所形成的向量。
梯度计算
有两种方法计算梯度:
数值梯度法 (实现简单 但是缓慢)
def eval_numerical_gradient(f, x):
"""
一个f在x处的数值梯度法的简单实现
- f是只有一个参数的函数
- x是计算梯度的点
"""
fx = f(x) # 在原点计算函数值
grad = np.zeros(x.shape)
h = 0.00001
# 对x中所有的item索引进行迭代
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# 计算x+h处的函数值
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # 增加h
fxh = f(x) # 计算f(x + h)
x[ix] = old_value # 存到前一个值中 (非常重要)
# 计算偏导数
grad[ix] = (fxh - fx) / h # 坡度
it.iternext() # 到下个维度
return grad
实际中用中心差值公式(centered difference formula)[f(x+h)-f(x-h)]/2h 效果较好 Numerical_differentiation
# 要使用上面的代码我们需要一个只有一个参数的函数
# (在这里参数就是权重)所以也包含了X_train和Y_train
def CIFAR10_loss_fun(W):
return L(X_train, Y_train, W)
W = np.random.rand(10, 3073) * 0.001 # 随机权重向量
df = eval_numerical_gradient(CIFAR10_loss_fun, W) # 得到梯度
loss_original = CIFAR10_loss_fun(W) # 初始损失值
print ‘original loss: %f’ % (loss_original, )
# 查看不同步长的效果
for step_size_log in [-10, -9, -8, -7, -6, -5,-4,-3,-2,-1]:
step_size = 10 ** step_size_log
W_new = W - step_size * df # 权重空间中的新位置
loss_new = CIFAR10_loss_fun(W_new)
print 'for step size %f new loss: %f' % (step_size, loss_new)
# 输出:
# original loss: 2.200718
# for step size 1.000000e-10 new loss: 2.200652
# for step size 1.000000e-09 new loss: 2.200057
# for step size 1.000000e-08 new loss: 2.194116
# for step size 1.000000e-07 new loss: 2.135493
# for step size 1.000000e-06 new loss: 1.647802
# for step size 1.000000e-05 new loss: 2.844355
# for step size 1.000000e-04 new loss: 25.558142
# for step size 1.000000e-03 new loss: 254.086573
# for step size 1.000000e-02 new loss: 2539.370888
# for step size 1.000000e-01 new loss: 25392.214036
步长的影响:梯度指明了函数在哪个方向?是变化率最大的 步长(也叫作学习率)
小步长下降稳定但进度慢 <-> 大步长进展快但是风险更大
在本例中有30730个参数,所以损失函数每走一步就需要计算30731次损失函数的梯度, 效率太低
分析梯度法 (计算迅速,结果精确) 微分分析计算梯度
用公式计算梯度速度很快,唯一不好的就是实现的时候容易出错. 于是我们需要将分析梯度法的结果于数值梯度法作比较, 这个步骤叫做梯度检查。
eg: SVM lossfunction
对W_yi 进行微分
梯度下降
普通版本
# 普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 进行梯度更新
小批量数据梯度下降(Mini-batch gradient descent)
每次小子集往下减少,小批量数据的梯度就是对整个数据集梯度的一个近似, 需要data的数量远大于小批数量
# 普通的小批量数据梯度下降
while True:
data_batch = sample_training_data(data, 256) # 256个数据
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 参数更新
随机梯度下降(Stochastic Gradient Descent 简称SGD)
如果小批量数据中每个批量只有1个数据样本
Summary:
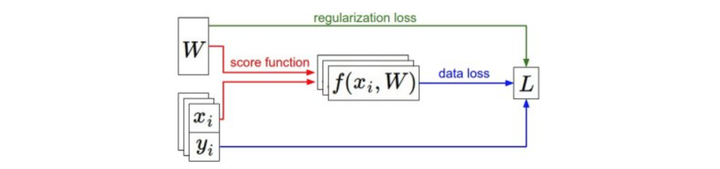
x,y 是给定的,weight 从一个随机开始,可以随时改变。 损失函数包含两个部分:数据损失和正则化损失,在梯度下降中,计算权重的维度实现参数的更新。