反向传播
Introduction:
反向传播是利用链式法则递归计算表达式的梯度的方法。 根据函数 f(x), 求关于f 关于 x的梯度 gradient

偏导数
(我的理解就是当对其中一个param 求导的时候视其他的params为const, 含义为当这个param 增加的时候 对f 的增加量的比值)
链式法则
Chain rule
这下面这个sample给的真的是清楚
x = -2; y = 5; z = -4
f(x,y,z) = (x+y)z
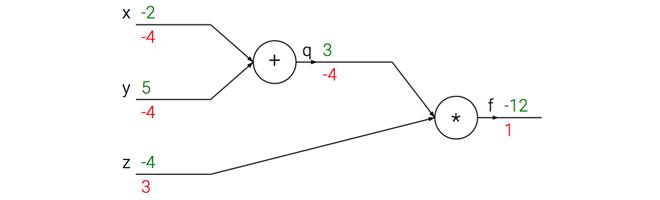
绿色的从输入端到输出端 为前向传播
红色的从输出端到输入端 为反向传播
反向传播的理解
反向传播是一个优美的局部过程。在整个计算线路图中,每个门单元都会得到一些输入并立即计算两个东西:
1.这个门的输出值,
2.其输出值关于输入值的局部梯度。
门单元完成这两件事是完全独立的,它不需要知道计算线路中的其他细节。然而,一旦前向传播完毕,在反向传播的过程中,门单元门将最终获得整个网络的最终输出值在自己的输出值上的梯度。链式法则指出,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。
因为在加法门中 是 y = a+b 所以slope 也就是梯度都是1, 在乘法门中 y = ab, 所以a 的梯度就是b, b的梯度就是a
Example
w = [2,-3,-3] # 假设一些随机数据和权重
x = [-1, -2]
# 前向传播
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid函数
# 对神经元反向传播
ddot = (1 - f) * f # 点积变量的梯度, 使用sigmoid函数求导
dx = [w[0] * ddot, w[1] * ddot] # 回传到x
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # 回传到w
# 完成!得到输入的梯度
Tip:
对前向传播变量进行缓存:在计算反向传播时,前向传播过程中得到的一些中间变量非常有用。在实际操作中,最好代码实现对于这些中间变量的缓存,这样在反向传播的时候也能用上它们。如果这样做过于困难,也可以(但是浪费计算资源)重新计算它们。
在不同分支的梯度要相加:如果变量x,y在前向传播的表达式中出现多次,那么进行反向传播的时候就要非常小心,使用+=而不是=来累计这些变量的梯度(不然就会造成覆写)。这是遵循了在微积分中的多元链式法则,该法则指出如果变量在线路中分支走向不同的部分,那么梯度在回传的时候,就应该进行累加。 比如 f(x,y) = sigmal(x) + x balabala
回传流中的模式
主要就是
加法门单元: 把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。这是因为加法操作的局部梯度都是简单的+1,所以所有输入的梯度实际上就等于输出的梯度,因为乘以1.0保持不变。上例中,加法门把梯度2.00不变且相等地路由给了两个输入。
y = 1.0 x a + 1.0 x b
取最大值门单元: 对梯度做路由。和加法门不同,取最大值门将梯度转给其中一个输入,这个输入是在前向传播中值最大的那个输入。这是因为在取最大值门中,最高值的局部梯度是1.0,其余的是0。上例中,取最大值门将梯度2.00转给了z变量,因为z的值比w高,于是w的梯度保持为0。
y = max(high, low) = 1.0 x high + 0 x low
乘法门单元: 相对不容易解释。它的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。上例中,x的梯度是-4.00x2.00=-8.00。
y = ab, a的梯度是b
用向量化操作计算梯度
其实就是矩阵相乘之类,作者建议通过维度来推测计算是否正确
Summary:
对梯度的含义有了直观理解,知道了梯度是如何在网络中反向传播的,知道了它们是如何与网络的不同部分通信并控制其升高或者降低,并使得最终输出值更高的。(梯度如何计算)
讨论了分段计算在反向传播的实现中的重要性。应该将函数分成不同的模块,这样计算局部梯度相对容易,然后基于链式法则将其“链”起来。重要的是,不需要把这些表达式写在纸上然后演算它的完整求导公式,因为实际上并不需要关于输入变量的梯度的数学公式。只需要将表达式分成不同的可以求导的模块(模块可以是矩阵向量的乘法操作,或者取最大值操作,或者加法操作等),然后在反向传播中一步一步地计算梯度。(不难理解,但是不知道实际操作是否需要,我感觉每一层都会有自己计算梯度的方法)